Towards Multiple Character Image Animation Through Enhancing Implicit Decoupling
ICLR25
Curry & Durant
Abstract
Controllable character image animation has a wide range of applications. Although existing studies have consistently improved performance, challenges persist in the field of character image animation, particularly concerning stability in complex backgrounds and tasks involving multiple characters. To address these challenges, we propose a novel multi-condition guided framework for character image animation, employing several well-designed input modules to enhance the implicit decoupling capability of the model. First, the optical flow guider calculates the background optical flow map as guidance information, which enables the model to implicitly learn to decouple the background motion into background constants and background momentum during training, and generate a stable background by setting zero background momentum during inference. Second, the depth order guider calculates the order map of the characters, which transforms the depth information into the positional information of multiple characters. This facilitates the implicit learning of decoupling different characters, especially in accurately separating the occluded body parts of multiple characters. Third, the reference pose map is input to enhance the ability to decouple character texture and pose information in the reference image. Furthermore, to fill the gap of fair evaluation of multi-character image animation in the community, we propose a new benchmark comprising approximately 4,000 frames. Extensive qualitative and quantitative evaluations demonstrate that our method excels in generating high-quality character animations, especially in scenarios of complex backgrounds and multiple characters.
Method
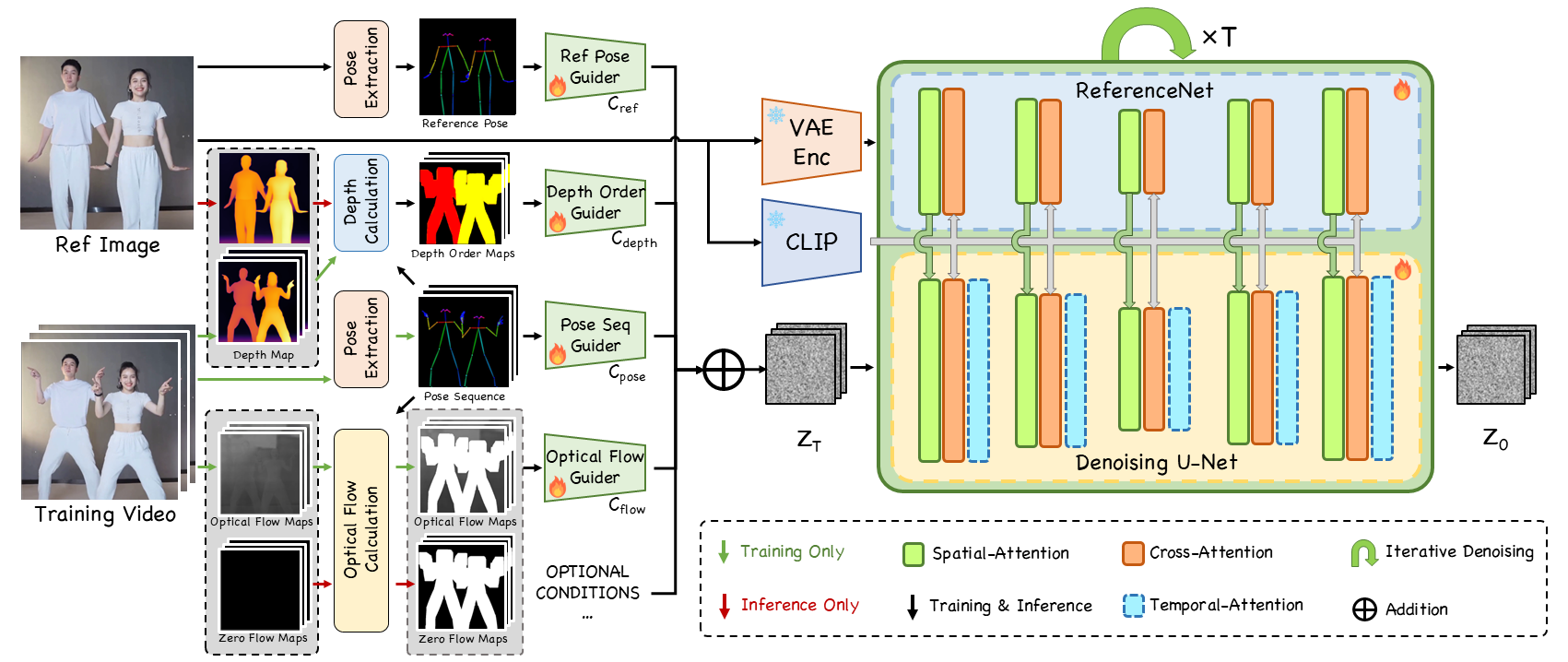
The overview of our method. The left half illustrates the data flow of the multiple condition guiders, with green and black arrows denoting training data flow, and red and black arrows indicating inference data flow. After processing the pose sequence/training video and reference images through the corresponding data flow, three condition maps are obtained. The pose sequence and three condition maps are incorporated into the initial multi-frame noise after being encoded separately by "Ref Pose Guider", "Depth Order Guider", "Pose Seq Guider", and "Optical Flow Guider" respectively. The right half shows the denoising U-Net and ReferenceNet. The initial noise is fed into U-Net for denoising to generate videos. After being encoded by VAE encoder, reference image is input into ReferenceNet to extract character features and then fed into the Spatial-Attention of U-Net for interaction. Furthermore, reference image is encoded by CLIP image encoder and then input into the Cross-Attention of U-Net and ReferenceNet for interaction. Note that the weights of U-Net and ReferenceNet are trainable, while the weights of both encoders are frozen.
Video Presentation
Gallery
Here we present more results to demonstrate the ability of our method to address various scenarios.
Single Character Animation.
Multiple Character Animation.
Different Pose.
Various Clothes.
Various Age.
Various Ethnicity.
Complex background.
BibTeX
@inproceedings{xuetowards,
title={Towards Multiple Character Image Animation Through Enhancing Implicit Decoupling},
author={Xue, Jingyun and Wang, Hongfa and Tian, Qi and Ma, Yue and Wang, Andong and Zhao, Zhiyuan and Min, Shaobo and Zhao, Wenzhe and Zhang, Kaihao and Shum, Heung-Yeung and others},
booktitle={The Thirteenth International Conference on Learning Representations}
}